The purpose of my new blogpost is to gain an intuition for converting tabular-structured data into graph-structured data and store into Graph database for further analysis using Neo4j.
Key Concepts
Definitions
A Graph Database uses graph structures with nodes, edges and properties to represent and store data. The graph relates data items to a collection of nodes and edges, where edges represent relationships between nodes. Graph database is designed to treat the relationships between data as important as the data itself.
The structure of a graph database relies on some key elements:
- Nodes — are the entities in graph. They can hold any number of attributes (key/value pairs) called properties. Nodes can be tagged labels, representing their different roles. Node labels also serve to attach metadata to certain nodes.
- Relationships — provide directed, named, semantically-relevant connections between two node entities. A relationship always has a type, a direction, a start node and an end node. Relationships can also have properties.
- Properties — Represent the named data values. Applicable to both nodes and relationships.
Neo4j (Network Exploration and Optimization 4 Java) is a graph database management system. Based on its official documentation, Neo4j is:
a native graph data store built from the ground up to leverage not only data but also data relationships. Unlike other types of databases, Neo4j connects data as it’s stored, enabling queries never before imagined, at speeds never thought possible.
Data Modeling to Graph
As a general approach, please review the Neo4j’s guide on converting relational databases to graph databases. A condensed summary of the steps to help you with the transformation of a relational diagram are listed below.
- Table to Node Label - each entity table in the relational model becomes a label on nodes in the graph model.
- Row to Node - each row in a relational entity table becomes a node in the graph.
- Columns (excluding Join keys) to Node Property - columns (fields) on the relational tables become node properties in the graph.
RELATIONAL DATABASE
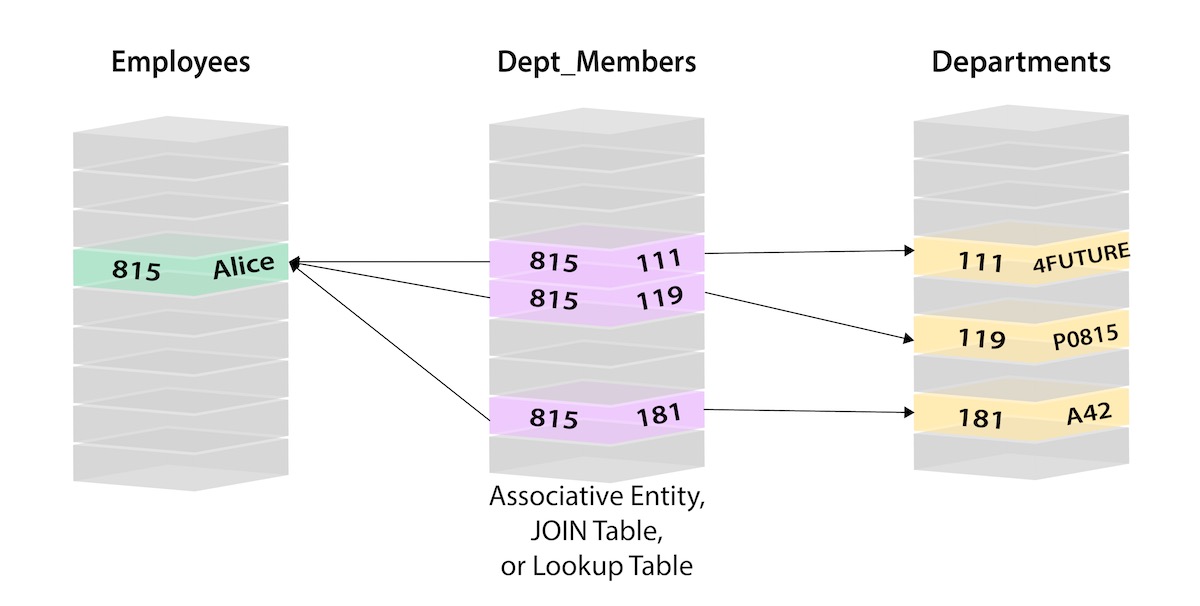

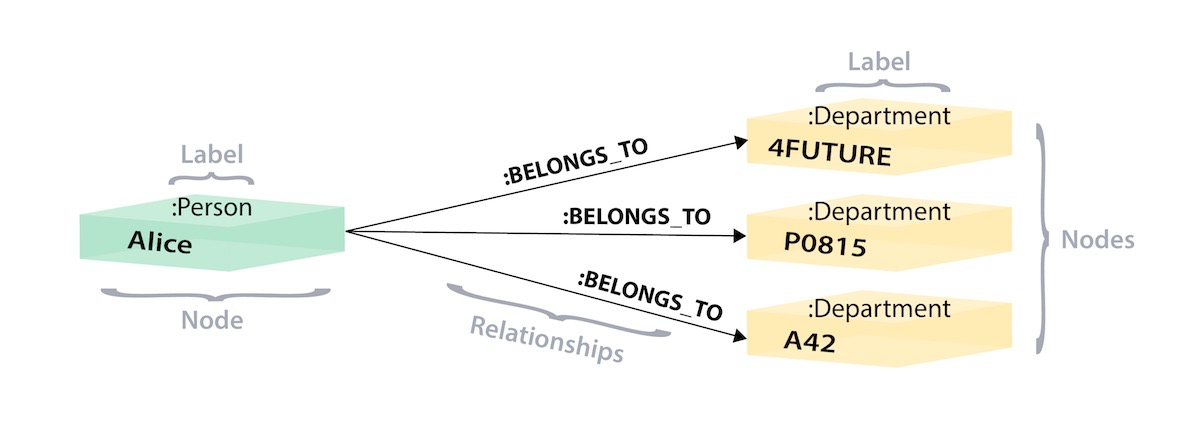
Cypher Query Language
Neo4j provides a powerful declarative language known as Cypher. Cypher is human-friendly query language that uses ASCII-Art, where (nodes)-[:ARE_CONNECTED_TO]->(otherNodes), to represent visual graph patterns for finding or updating data in a graph database. For example:
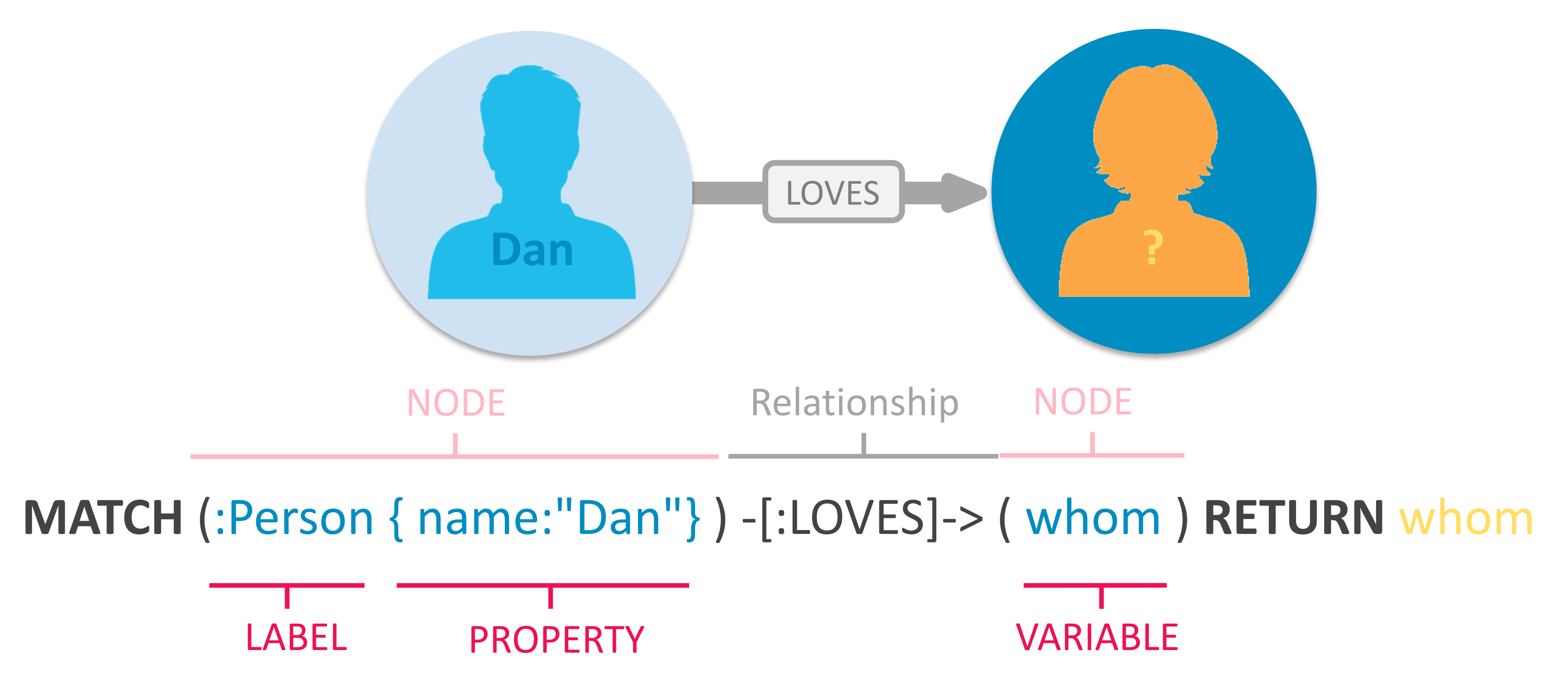
Neo4j users use Cypher to construct expressive and efficient queries to do any kind of create, read, update, or delete (CRUD) on their graph. Additionally, Cypher is the primary interface for Neo4j.
Practical Use-Case: NorthWind Database
Now that we have explored some key concepts, let’s dive into an actual example. For that matter, I am going to use the NorthWind dataset which provides information about a product sale system on - suppliers, products, order details, categories, employees, & orders. The entity-relationship diagram is shown below:
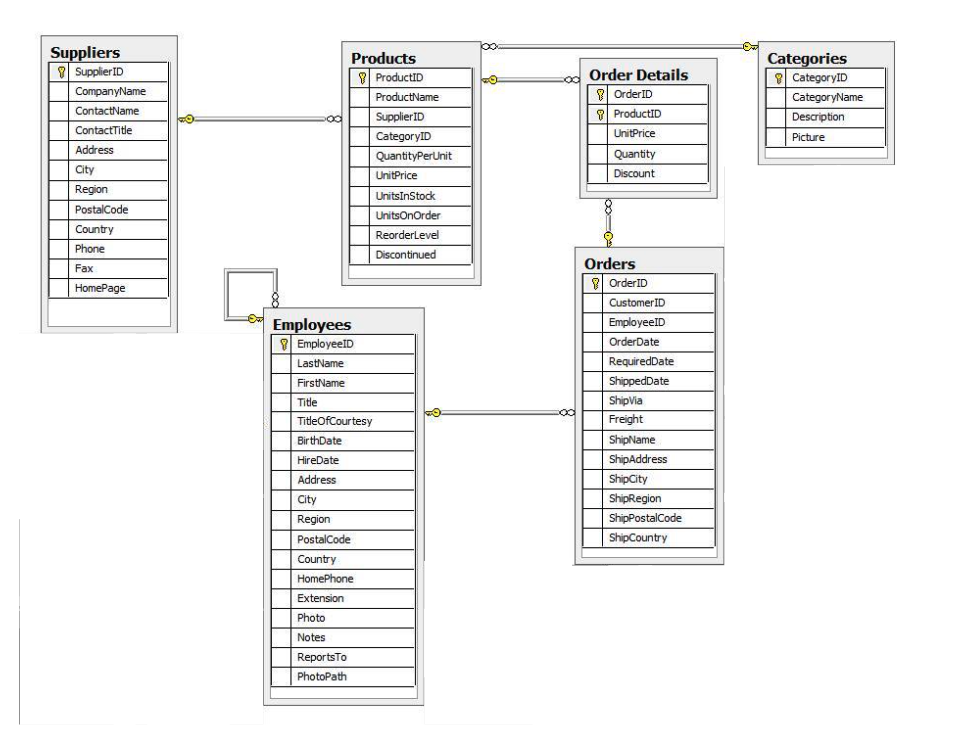
Applying the principles explored above, I can convert this set of tabular data into graph data as follows:
Rows to Nodes
- Each row on our
Orderstable becomes a node in our graph withOrderas the label. - Each row on our
Productstable becomes a node withProductas the label. - Each row on our
Supplierstable becomes a node withSupplieras the label. - Each row on our
Categoriestable becomes a node withCategoryas the label. - Each row on our
Employeestable becomes a node withEmployeeas the label.
Joins to relationships
- Join between
SuppliersandProductsbecomes a relationship namedSUPPLIES(where supplier supplies product). - Join between
ProductsandCategoriesbecomes a relationship namedPART_OF(where product is part of a category). - Join between
EmployeesandOrdersbecomes a relationship namedSOLD(where employee sold an order). - Join between
Employeesand itself (unary relationship) becomes a relationship namedREPORTS_TO(where employees have a manager). - Join with join table (
Order Details) betweenOrdersandProductsbecomes a relationship namedCONTAINSwith properties ofunitPrice,quantity, anddiscount(where order contains a product).
Technology stack
Our entire technology can be summarised looking at this YAML file:
version: '3.8'
services:
neo4j:
container_name: neo4j
image: neo4j:4.4.3-community
ports:
- 7888:7474
- 7999:7687
restart: unless-stopped
networks:
- db
environment:
- NEO4J_AUTH=neo4j/password
volumes:
- ./db/data:/data
- ./db/conf:/conf
- ./db/logs:/logs
- ./db/plugins:/plugins
- ./db/scripts:/var/lib/neo4j/scripts
pgdatabase:
container_name: db
image: postgres:latest
restart: always
environment:
- POSTGRES_USER=root
- POSTGRES_PASSWORD=root
- POSTGRES_DB=northwind
volumes:
- ./scripts/northwind_postgres.sql:/docker-entrypoint-initdb.d/northwind_postgres.sql
ports:
- 5432:5432
networks:
- db
pgadmin:
container_name: pgadmin
image: dpage/pgadmin4
environment:
- PGADMIN_DEFAULT_EMAIL=admin@admin.com
- PGADMIN_DEFAULT_PASSWORD=postgres
- PGADMIN_LISTEN_PORT=5050
- PGADMIN_CONFIG_SERVER_MODE=False
ports:
- 5050:5050
networks:
db:
driver: bridgeLooking at the Docker-Compose yaml file, there are three different items needed to build my working environment:
- Neo4j Docker Image which is a standard, ready-to-run pacakge of Neo4j. The neo4j container will be exposed via port
7999. - Postgres Docker Image which is a data warehouse to generate and store the NorthWind dataset locally. The postgres container will be exposed via port
5432. - PgAdmin Docker Image which is a standard graphical tool to query data from Postgres. The pgAdmin container will be exposed via port
5050.
Additionally, I will be using Neo4j Desktop to run cypher queries on the newly created graph database using this connection URL neo4j://localhost:7999.
Once all the applications have been installed, running Docker-Compose will do this
> docker-compose up
...
....Lots of messages....
...
Creating Neo4j ... done
Creating pgadmin ... done
Creating db ... done
...When it comes to integrate Neo4j with other databases, the APOC library offers support including relational databases (via JDBC), MongoDB, Elastic, and Couchbase. It also has support for importing data from LDAP directories and executing queries against other Neo4j databases. Here is the link to find out more.
For this example, I am importing the NorthWind database from PostGres straight into Neo4j. The syntax will look like this:
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", <table_name/query>)Create Nodes and Relationships
Create Nodes
Orders nodes
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "orders") YIELD row
MERGE (order:Order {orderID: row.order_id})
ON CREATE SET order.shipName = row.ship_name;Added 830 labels, created 830 nodes, set 1660 properties, completed after 1149 ms.
Products nodes
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "products") YIELD row
MERGE (product:Product {productID: row.product_id})
ON CREATE SET product.productName = row.product_name, product.unitPrice = toFloat(row.unit_price);Added 77 labels, created 77 nodes, set 231 properties, completed after 75 ms.
Suppliers nodes
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "suppliers") YIELD row
MERGE (supplier:Supplier {supplierID: row.supplier_id})
ON CREATE SET supplier.companyName = row.company_name;Added 29 labels, created 29 nodes, set 58 properties, completed after 30 ms.
Employees nodes
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "employees") YIELD row
MERGE (e:Employee {employeeID:row.employee_id})
ON CREATE SET e.firstName = row.first_name, e.lastName = row.last_name, e.title = row.title;Added 9 labels, created 9 nodes, set 36 properties, completed after 38 ms.
Categories nodes
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "categories") YIELD row
MERGE (c:Category {categoryID: row.category_id})
ON CREATE SET c.categoryName = row.category_name, c.description = row.description;Added 8 labels, created 8 nodes, set 24 properties, completed after 31 ms.
To ensure the lookup of nodes is optimized, I created indexes for any node properties used in the lookups (often the id or another unique value).
CREATE INDEX product_id FOR (p:Product) ON (p.productID);
CREATE INDEX product_name FOR (p:Product) ON (p.productName);
CREATE INDEX supplier_id FOR (s:Supplier) ON (s.supplierID);
CREATE INDEX employee_id FOR (e:Employee) ON (e.employeeID);
CREATE INDEX category_id FOR (c:Category) ON (c.categoryID);
CREATE CONSTRAINT order_id ON (o:Order) ASSERT o.orderID IS UNIQUE;
CALL db.awaitIndexes();Create Relationships
I will focus on creating the following relationships
Create relationships between orders and products
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "order_details") YIELD row
MATCH (order:Order {orderID: row.order_id})
MATCH (product:Product {productID: row.product_id})
MERGE (order)-[op:CONTAINS]->(product)
ON CREATE SET op.unitPrice = toFloat(row.unit_price), op.quantity = toFloat(row.quantity);Set 4310 properties, created 2155 relationships, completed after 876 ms.
Create relationships between orders and employees
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "orders") YIELD row
MATCH (order:Order {orderID: row.order_id})
MATCH (employee:Employee {employeeID: row.employee_id})
MERGE (employee)-[:SOLD]->(order);Created 830 relationships, completed after 177 ms.
Create relationships between products and suppliers
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "products") YIELD row
MATCH (product:Product {productID: row.product_id})
MATCH (supplier:Supplier {supplierID: row.supplier_id})
MERGE (supplier)-[:SUPPLIES]->(product);Created 77 relationships, completed after 60 ms.
Create relationships between products and categories
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "products") YIELD row
MATCH (product:Product {productID: row.product_id})
MATCH (category:Category {categoryID: row.category_id})
MERGE (product)-[:PART_OF]->(category);Created 77 relationships, completed after 53 ms.
Create relationships between employees (reporting hierarchy)
CALL apoc.load.jdbc("jdbc:postgresql://pgdatabase/northwind?user=root&password=root", "employees") YIELD row
MATCH (employee:Employee {employeeID: row.employee_id})
MATCH (manager:Employee {employeeID: row.reports_to})
MERGE (employee)-[:REPORTS_TO]->(manager);Created 8 relationships, completed after 46 ms.
Query the Graph Database
Now that I created my graph database, I can query it to answer a few business questions:
- What are the top 5 most popular products?
- Who is the supplier and what is the category for the top product?
- Who are the top 3 Employees with the Highest Cross-Selling Count of the top product and Another Product?
What are the top 5 most popular products?
match (o:Order)-[:CONTAINS]->(p:Product)
return p.productName as productName, count(o) as orders
order by orders desc, productName asc
limit 5Answer
| productName | orders |
|---|---|
| “Raclette Courdavault” | 54 |
| “Camembert Pierrot” | 51 |
| “Gorgonzola Telino” | 51 |
| “Guaraná Fantástica” | 51 |
| “Gnocchi di nonna Alice” | 50 |
Who is the supplier and what is the category for the top product?
MATCH (s:Supplier)-[r1:SUPPLIES]->(p:Product {productName: 'Raclette Courdavault'})-[r2:PART_OF]->(c:Category)
RETURN s, r1, p, r2, c;Answer

Who is the top Employee with the Highest Cross-Selling Count of the top product and Another Product?
MATCH (choc:Product {productName:'Raclette Courdavault'})<-[:CONTAINS]-(:Order)<-[:SOLD]-(employee),
(employee)-[:SOLD]->(o2)-[:CONTAINS]->(other:Product)
RETURN employee.employeeID as employee, other.productName as otherProduct, count(distinct o2) as count
ORDER BY count DESC
LIMIT 1;Answer
| employee | otherProduct | count |
|---|---|---|
| 4 | “Gnocchi di nonna Alice” | 14 |
Closing notes
So for this blogpost, I introduced Neo4j and what can be done with it. It is worth mentioning that modeling your tabular data as graph data depends on your use-case. The methodology described above provides a framework, but you might come up with a useful representation.
However, you may have to ask yourself the following question: are there relationships between my datapoints that will help me solve a specific task? It’s not always clear in advance, and some exploratory data analysis can be helpful. There can be some ambiguity in whether a column should be a node or a node property. For example, the country of a user could be a property of the User node, or might be its own node that relates users via a user-lives_in-country relationship. There is no single answer, and it will likely require experimentation to find an optimal representation for the task at hand.
I hope you enjoyed reading this blogpost :)
Here is the link to GitHub repository with all my codes: https://github.com/franckess/neo4j_practice/tree/master
